
The ABCs of Machine Learning: Essential Algorithms for Every Data Scientist
Machine learning is a powerful tool that allows computers to learn from data and make decisions without being explicitly programmed. Whether it’s predicting sales, classifying emails, or recommending products, machine learning algorithms can solve a variety of problems.
In this article, let’s understand some of the most commonly used machine learning algorithms.
What Are Machine Learning Algorithms?
Machine learning algorithms are mathematical models designed to analyze data, recognize patterns, and make predictions or decisions. There are many different types of algorithms, and each one is suited for a specific type of task.
Common Types of Machine Learning Algorithms
Let’s look at some of the most popular machine learning algorithms, divided into key categories:
1. Linear Regression
- Type: Supervised Learning (Regression)
- Purpose: Predict continuous values (e.g., predicting house prices based on features like area and location).
- How it works: Linear regression finds a straight line that best fits the data points, predicting an output (Y) based on the input (X) using the formula:
Y=mX+c
Where Y is the predicted output, X is the input feature, m is the slope of the line, and c is the intercept.
- Example: Predicting the price of a house based on its size.
2. Logistic Regression
- Type: Supervised Learning (Classification)
- Purpose: Classify binary outcomes (e.g., whether a customer will buy a product or not).
- How it works: Logistic regression predicts the probability of an event occurring. The outcome is categorical (yes/no, 0/1) and is predicted using a sigmoid function, which outputs values between 0 and 1.
- Example: Predicting whether a student will pass an exam based on study hours.
3. Decision Trees
- Type: Supervised Learning (Classification and Regression)
- Purpose: Make decisions by splitting data into smaller subsets based on certain features.
- How it works: A decision tree splits the data into branches based on conditions, creating a tree-like structure. Each branch represents a decision rule, and the leaves represent the final outcome (classification or prediction).
- Example: Deciding whether a loan applicant should be approved based on factors like income, age, and credit score.
4. Random Forest
- Type: Supervised Learning (Classification and Regression)
- Purpose: Improve accuracy by combining multiple decision trees.
- How it works: Random forest creates a large number of decision trees, each using a random subset of the data. The predictions from all the trees are combined to give a more accurate result.
- Example: Predicting whether a customer will churn based on service usage and customer support history.
5. K-Nearest Neighbors (KNN)
- Type: Supervised Learning (Classification and Regression)
- Purpose: Classify or predict outcomes based on the majority vote of nearby data points.
- How it works: KNN assigns a new data point to the class that is most common among its K nearest neighbors. The value of K is chosen based on the problem at hand.
- Example: Classifying whether an email is spam or not by comparing it with the content of similar emails.
6. Support Vector Machine (SVM)
- Type: Supervised Learning (Classification)
- Purpose: Classify data by finding the best boundary (hyperplane) that separates different classes.
- How it works: SVM tries to find the line or hyperplane that best separates the data into different classes. It maximizes the margin between the classes, ensuring that the data points are as far from the boundary as possible.
- Example: Classifying whether a tumor is benign or malignant based on patient data.
7. Naive Bayes
- Type: Supervised Learning (Classification)
- Purpose: Classify data based on probabilities using Bayes’ Theorem.
- How it works: Naive Bayes calculates the probability of each class given the input features. It assumes that all features are independent (hence “naive”), even though this may not always be true.
- Example: Classifying emails as spam or not spam based on word frequency.
8. K-Means Clustering
- Type: Unsupervised Learning (Clustering)
- Purpose: Group similar data points into clusters.
- How it works: K-means divides the data into K clusters by finding the centroids of each cluster and assigning data points to the nearest centroid. The process continues until the centroids stop moving.
- Example: Segmenting customers into groups based on their purchasing behavior.
9. Principal Component Analysis (PCA)
- Type: Unsupervised Learning (Dimensionality Reduction)
- Purpose: Reduce the number of input features while retaining the most important information.
- How it works: PCA reduces the number of features by identifying which ones explain the most variance in the data. This helps simplify complex datasets without losing significant information.
- Example: Reducing the number of variables in a dataset for better visualization or faster model training.
10. Time Series Forecasting: ARIMA
- Type: Supervised Learning (Time Series Forecasting)
- Purpose: Predict future values based on historical time series data.
- How it works: ARIMA (AutoRegressive Integrated Moving Average) is a widely used algorithm for time series forecasting. It models the data based on its own past values (autoregressive part), the difference between consecutive observations (integrated part), and a moving average of past errors (moving average part).
- Example: Forecasting stock prices or predicting future sales based on past sales data.
11. Gradient Boosting (e.g., XGBoost)
- Type: Supervised Learning (Classification and Regression)
- Purpose: Improve prediction accuracy by combining many weak models.
- How it works: Gradient boosting builds models sequentially, where each new model corrects the errors made by the previous ones. XGBoost (Extreme Gradient Boosting) is one of the most popular gradient boosting algorithms because of its speed and accuracy.
- Example: Predicting customer behavior or product demand.
12. Neural Networks
- Type: Supervised Learning (Classification and Regression)
- Purpose: Model complex relationships between input and output by mimicking the human brain.
- How it works: Neural networks consist of layers of interconnected nodes (neurons) that process input data. The output of one layer becomes the input to the next, allowing the network to learn hierarchical patterns in the data. Deep learning models, like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), are built on this concept.
- Example: Image recognition, voice recognition, and language translation.
13. Convolutional Neural Networks (CNNs)
- Type: Deep Learning (Supervised Learning for Classification)
- Purpose: Primarily used for image and video recognition tasks.
- How it works: CNNs are designed to process grid-like data such as images. They use a series of convolutional layers to automatically detect patterns, like edges or textures, in images. Each layer extracts higher-level features from the input data, allowing the network to “learn” how to recognize objects.
- Example: Classifying images of cats and dogs, or facial recognition.
14. Recurrent Neural Networks (RNNs)
- Type: Deep Learning (Supervised Learning for Sequential Data)
- Purpose: Designed for handling sequential data, such as time series, natural language, or speech data.
- How it works: RNNs have a looping mechanism that allows information to be passed from one step of the sequence to the next. This makes them especially good at tasks where the order of the data matters, like language translation or speech recognition.
- Example: Predicting the next word in a sentence or generating text.
15. Long Short-Term Memory (LSTM)
- Type: Deep Learning (Supervised Learning for Sequential Data)
- Purpose: A type of RNN specialized for learning long-term dependencies in sequential data.
- How it works: LSTMs improve upon traditional RNNs by adding mechanisms to learn what to keep or forget over longer sequences. This helps solve the problem of vanishing gradients, where standard RNNs struggle to learn dependencies across long sequences.
- Example: Predicting stock prices, speech recognition, and language modeling.
16. Generative Adversarial Networks (GANs)
- Type: Deep Learning (Unsupervised Learning for Generative Modeling)
- Purpose: Generate new data samples that are similar to the training data (e.g., generating realistic images).
- How it works: GANs consist of two networks: a generator and a discriminator. The generator creates new data instances, while the discriminator evaluates whether they are real or fake. They work together in a feedback loop where the generator improves over time until it creates realistic data that fools the discriminator.
- Example: Generating realistic-looking images, creating deepfake videos, or synthesizing art.
17. Autoencoders
- Type: Deep Learning (Unsupervised Learning for Data Compression and Reconstruction)
- Purpose: Learn efficient data encoding by compressing data into a smaller representation and then reconstructing it.
- How it works: Autoencoders are neural networks that try to compress the input data into a smaller “bottleneck” representation and then reconstruct it. They are often used for dimensionality reduction, anomaly detection, or even data denoising.
- Example: Reducing noise in images or compressing high-dimensional data like images or videos.
18. Natural Language Processing (NLP) Algorithms
a. Bag of Words (BoW)
- Type: NLP (Text Representation)
- Purpose: Represent text data by converting it into word frequency counts, ignoring the order of words.
- How it works: In BoW, each document is represented as a “bag” of its words, and the model simply counts how many times each word appears in the text. It’s useful for simple text classification tasks but lacks context about the order of words.
- Example: Classifying whether a movie review is positive or negative based on word frequency.
b. TF-IDF (Term Frequency-Inverse Document Frequency)
- Type: NLP (Text Representation)
- Purpose: Represent text data by focusing on how important a word is to a document in a collection of documents.
- How it works: TF-IDF takes into account how frequently a word appears in a document (term frequency) and how rare or common it is across multiple documents (inverse document frequency). This helps to highlight significant words in a text while reducing the weight of commonly used words like “the” or “is.”
- Example: Identifying key terms in scientific papers or news articles.
c. Word2Vec
- Type: NLP (Word Embeddings)
- Purpose: Convert words into continuous vectors of numbers that capture semantic relationships.
- How it works: Word2Vec trains a shallow neural network to represent words as vectors in such a way that words with similar meanings are close to each other in vector space. It’s particularly useful in capturing word relationships like “king” being close to “queen.”
- Example: Using word embeddings for document similarity or recommendation systems based on textual data.
d. Transformer Models
- Type: Deep Learning (NLP)
- Purpose: Handle complex language tasks such as translation, summarization, and question answering.
- How it works: Transformer models, like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), use attention mechanisms to understand context by processing all words in a sentence at once. This allows them to capture both the meaning and relationships between words efficiently.
- Example: Automatically translating text between languages or summarizing articles.
19. Generative AI Models
a. GPT (Generative Pre-trained Transformer)
- Type: Deep Learning (Generative AI for Text)
- Purpose: Generate human-like text based on given prompts.
- How it works: GPT models are based on the Transformer architecture and are trained on massive datasets to predict the next word in a sequence. Over time, these models learn to generate coherent text that follows the input context, making them excellent for content creation, dialogue systems, and language translation.
- Example: Writing essays, generating chatbot conversations, or answering questions based on a given text.
b. BERT (Bidirectional Encoder Representations from Transformers)
- Type: Deep Learning (NLP)
- Purpose: Understand the meaning of a sentence by considering the context of each word in both directions.
- How it works: BERT is a transformer model trained to predict masked words within a sentence, allowing it to capture the full context around a word. This bidirectional understanding makes it highly effective for tasks like sentiment analysis, question answering, and named entity recognition.
- Example: Answering questions about a paragraph or finding relevant information in a document.
c. DALL-E / Microsoft Bing Co-Pilot
- Type: Deep Learning (Generative AI for Images from Text)
- Purpose: Generate images based on textual descriptions.
- How it works: DALL-E for instance, developed by OpenAI, uses a combination of language models and image generation techniques to create detailed images from text prompts. This model can understand the content of text prompts and create corresponding visual representations.
- Example: Generating an image of “a cat playing a guitar in space” based on a simple text description.
d. Stable Diffusion
- Type: Generative AI (Text-to-Image Models)
- Purpose: Generate high-quality images from text descriptions or prompts.
- How it works: Stable Diffusion models use a process of denoising and refinement to create realistic images from random noise, guided by a text description. They have become popular for their ability to generate creative artwork, photorealistic images, and illustrations based on user input.
- Example: Designing visual content for marketing campaigns or creating AI-generated artwork.
20. Reinforcement Learning (RL)
- Type: Machine Learning (Learning by Interaction)
- Purpose: Learn to make decisions by interacting with an environment to maximize cumulative rewards.
- How it works: In RL, an agent learns by taking actions in an environment, receiving feedback in the form of rewards or penalties, and adjusting its behavior to maximize the total reward over time. RL is widely used in areas where decisions need to be made sequentially, like robotics, game playing, and autonomous systems.
- Example: AlphaGo, a program that defeated the world champion in the game of Go, and autonomous driving systems.
21. Transfer Learning
- Type: Machine Learning (Reusing Pretrained Models)
- Purpose: Reuse a pre-trained model on a new but related task, reducing the need for extensive new training data.
- How it works: Transfer learning leverages the knowledge from a model trained on one task (such as image classification) and applies it to another task with minimal fine-tuning. It’s especially useful when there’s limited labeled data available for the new task.
- Example: Using a pre-trained model like BERT for sentiment analysis with only minor adjustments.
22. Semi-Supervised Learning
- Type: Machine Learning (Combination of Supervised and Unsupervised)
- Purpose: Learn from a small amount of labeled data along with a large amount of unlabeled data.
- How it works: Semi-supervised learning combines both labeled and unlabeled data to improve learning performance. It’s a valuable approach when acquiring labeled data is expensive, but there’s an abundance of unlabeled data. Models are trained first on labeled data and then refined using the unlabeled portion.
- Example: Classifying emails as spam or not spam, where only a small fraction of the emails are labeled.
23. Self-Supervised Learning
- Type: Machine Learning (Learning from Raw Data)
- Purpose: Automatically create labels from raw data to train a model without manual labeling.
- How it works: In self-supervised learning, models are trained using a portion of the data as input and another part of the data as the label. For example, models may predict masked words in a sentence (as BERT does) or predict future video frames from previous ones. This allows models to leverage vast amounts of raw, unlabeled data.
- Example: Facebook’s SEER model, which trains on billions of images without human-annotated labels.
24. Meta-Learning (“Learning to Learn”)
- Type: Machine Learning (Optimizing Learning Processes)
- Purpose: Train models that can quickly adapt to new tasks by learning how to learn from fewer examples.
- How it works: Meta-learning focuses on creating algorithms that learn how to adjust to new tasks quickly. Rather than training a model from scratch for every new task, meta-learning optimizes the learning process itself, so the model can generalize across tasks.
- Example: Few-shot learning models that can generalize from just a handful of training examples for tasks like image classification or text understanding.
25. Federated Learning
- Type: Machine Learning (Privacy-Preserving Learning)
- Purpose: Train machine learning models across decentralized devices without sharing sensitive data.
- How it works: Federated learning allows a central model to be trained across decentralized devices or servers (e.g., smartphones) without sending raw data to a central server. Instead, the model is trained locally on each device, and only the model updates are sent to a central server, maintaining data privacy.
- Example: Federated learning is used by Google for improving mobile keyboard predictions (e.g., Gboard) without directly accessing users’ typed data.
26. Attention Mechanisms (Used in Transformers)
- Type: Deep Learning (For Sequence Data)
- Purpose: Focus on the most relevant parts of input data when making predictions.
- How it works: Attention mechanisms allow models to focus on specific parts of input data (e.g., words in a sentence) based on relevance to the task at hand. This is a core component of the Transformer models like BERT and GPT, and it enables these models to handle long-range dependencies in data effectively.
- Example: In machine translation, attention allows the model to focus on specific words in the source sentence when generating each word in the target language.
27. Zero-Shot Learning
- Type: Machine Learning (Generalizing to New Classes)
- Purpose: Predict classes that the model hasn’t explicitly seen in training by using auxiliary information like textual descriptions.
- How it works: Zero-shot learning enables models to classify data into classes that were not part of the training set. This is often achieved by connecting visual or other types of data with semantic descriptions (e.g., describing the attributes of an unseen animal).
- Example: Classifying a new animal species that the model hasn’t seen before by understanding descriptions of its attributes (e.g., “has fur,” “four legs”).
Final Thoughts
Machine learning offers a variety of algorithms designed to solve different types of problems. Here’s a quick summary:
- Supervised Learning algorithms like Linear Regression, Decision Trees, and SVM make predictions or classifications based on labeled data.
- Unsupervised Learning algorithms like K-Means Clustering and PCA find patterns or reduce the complexity of unlabeled data.
- Time Series Forecasting algorithms like ARIMA predict future values based on past data.
- Ensemble Methods like Random Forest and XGBoost combine multiple models to improve accuracy.
- Convolutional Neural Networks (CNNs) for image processing
- Recurrent Neural Networks (RNNs) and LSTMs for handling sequential data
- Generative Adversarial Networks (GANs) for creating new data samples
- Autoencoders for data compression and reconstruction
- Bag of Words (BoW) and TF-IDF for simple text representation.
- Word2Vec and Transformer Models like BERT and GPT for deep language understanding.
- Generative AI models like GPT for text generation, DALL-E and Stable Diffusion for image generation, offering creative capabilities far beyond what traditional models can do.
Understanding the strengths and weaknesses of these algorithms will help us choose the right one for our specific task. As we continue learning and practicing these, we will gain a deeper understanding of how these algorithms work and when to use them. Happy learning!







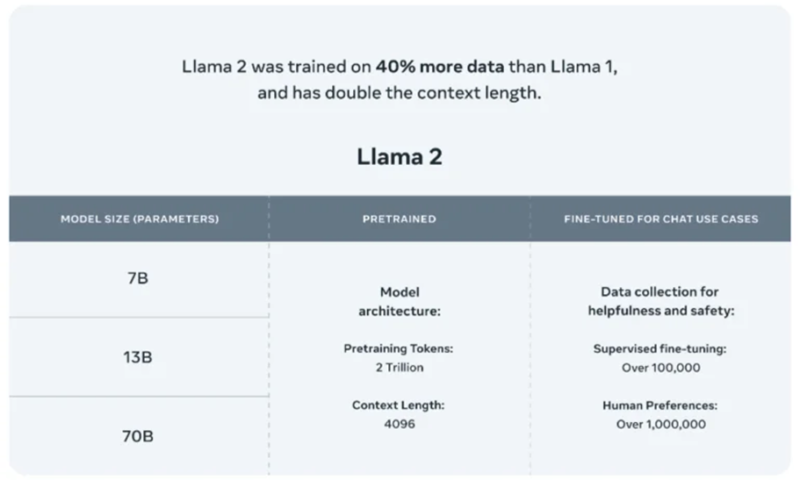
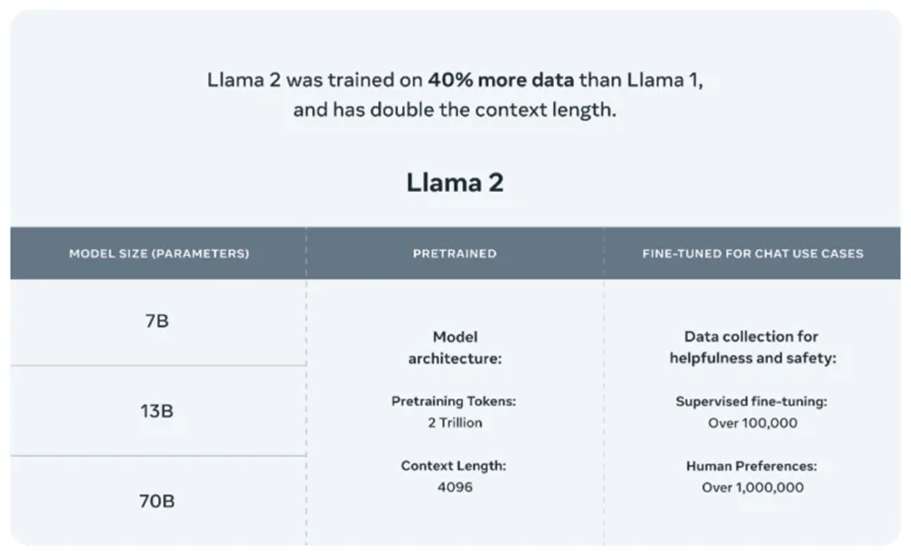
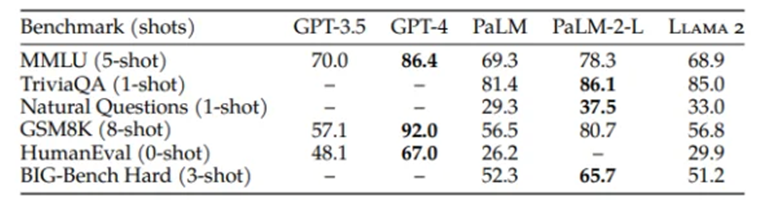





















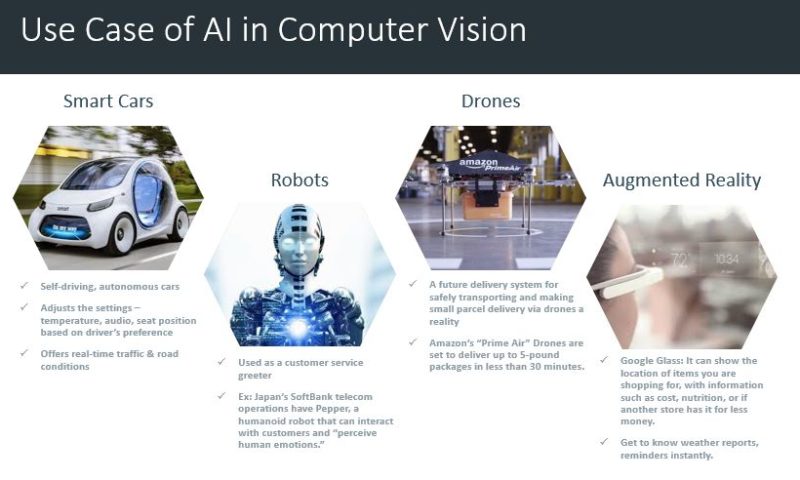
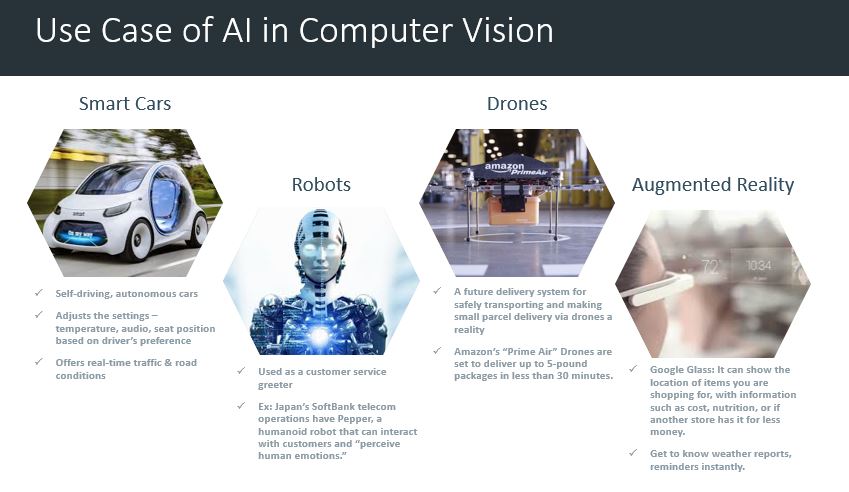 1. Computer Vision – Smart Cars (Autonomous Cars): IBM survey results say 74% expected that we would see smart cars on the road by 2025. It might adjust the internal settings — temperature, audio, seat position, etc. — automatically based on the driver, report and even fix problems itself, drive itself, and offer real time advice about traffic and road conditions.
1. Computer Vision – Smart Cars (Autonomous Cars): IBM survey results say 74% expected that we would see smart cars on the road by 2025. It might adjust the internal settings — temperature, audio, seat position, etc. — automatically based on the driver, report and even fix problems itself, drive itself, and offer real time advice about traffic and road conditions.