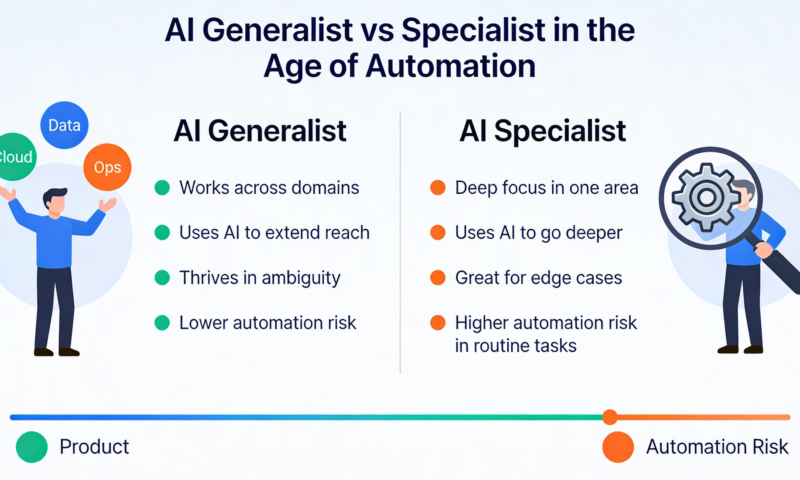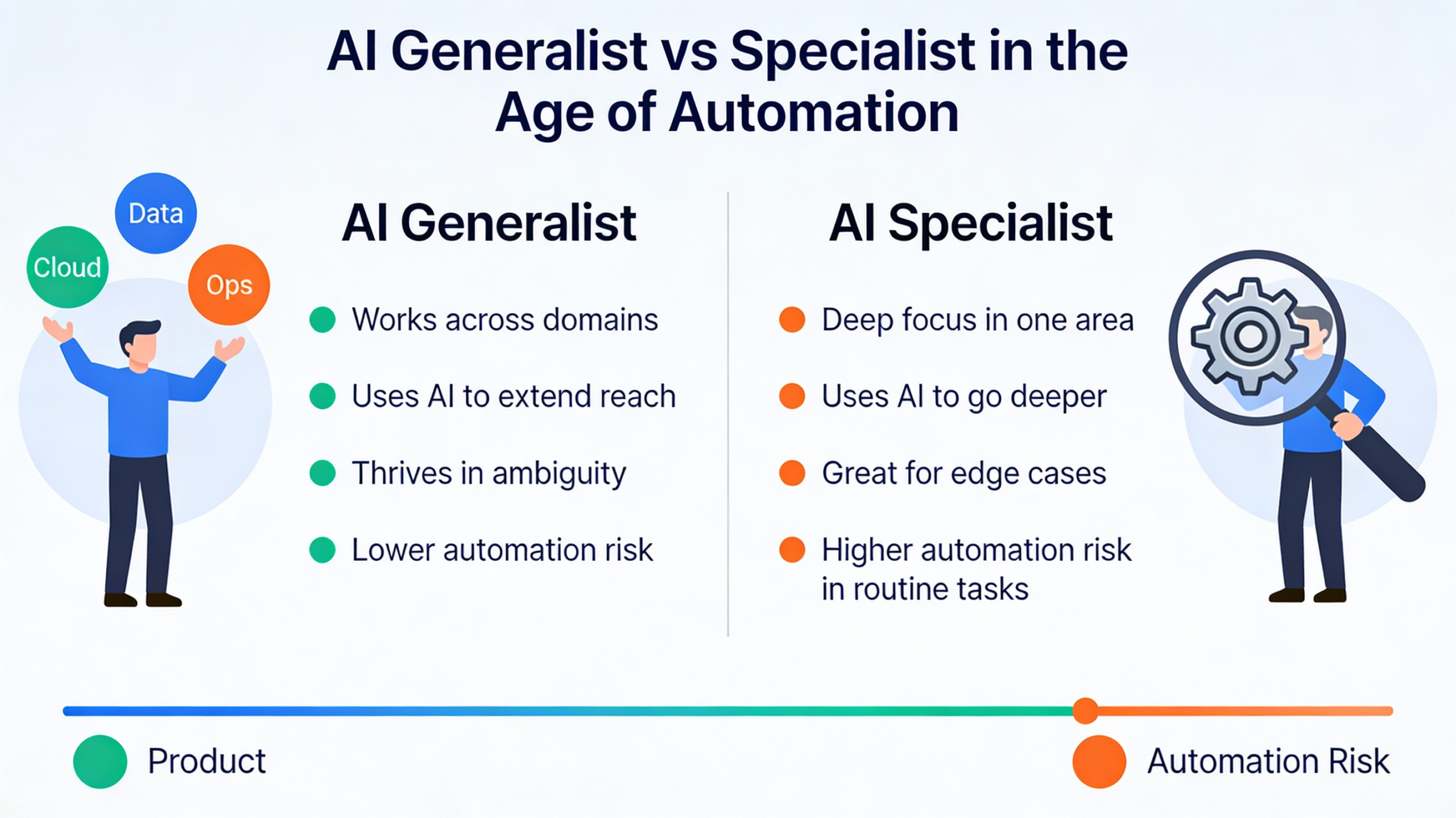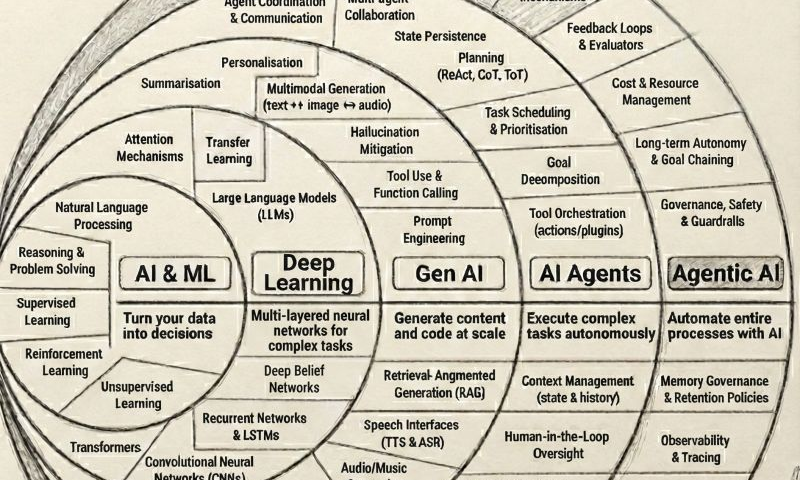
Agentic AI Is Not Just Multi-Threading With a Fancy Hat
A friendly reality check for developers who’ve been there, coded that
If you’ve spent years writing Java or C#, your brain has a beautiful superpower: you see new problems through the lens of patterns you already know. Concurrency, thread pools, executors – these are your comfort zone. So when someone says “AI agents run multiple tasks in parallel”, your brain fires up the old mental model: oh, so it’s like threads. Got it.
Totally understandable. And also, respectfully, kind of wrong. Not completely wrong, but wrong enough that it’ll trip you up when you try to actually build or work with agentic AI systems.
Let’s fix that, with zero jargon and a bunch of real examples.
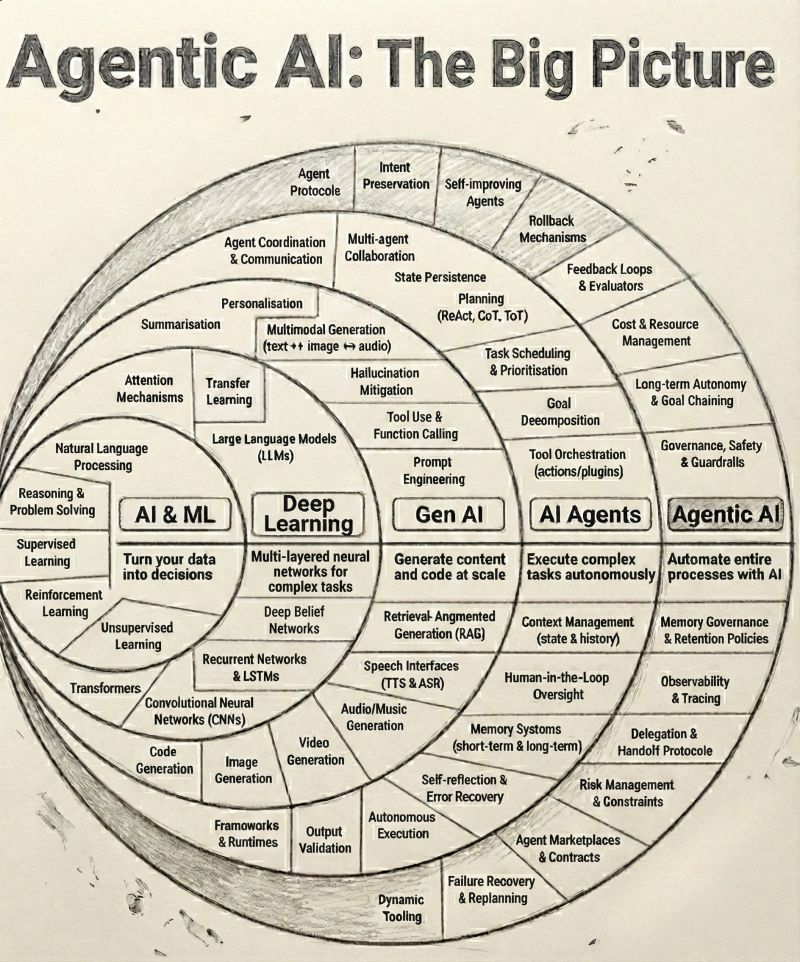
What Even Is Agentic AI?
Regular AI, like a basic chatbot or a GPT prompt, is reactive. You give it an input, it gives you an output. One shot. Done.
Agentic AI is proactive. You give it a goal, and it figures out the steps, uses tools, makes decisions, and keeps going until the job is done or it hits a wall and asks you for help.
Think of it like this: regular AI is a vending machine. Agentic AI is an intern with a to-do list, a laptop, and access to your company Slack.
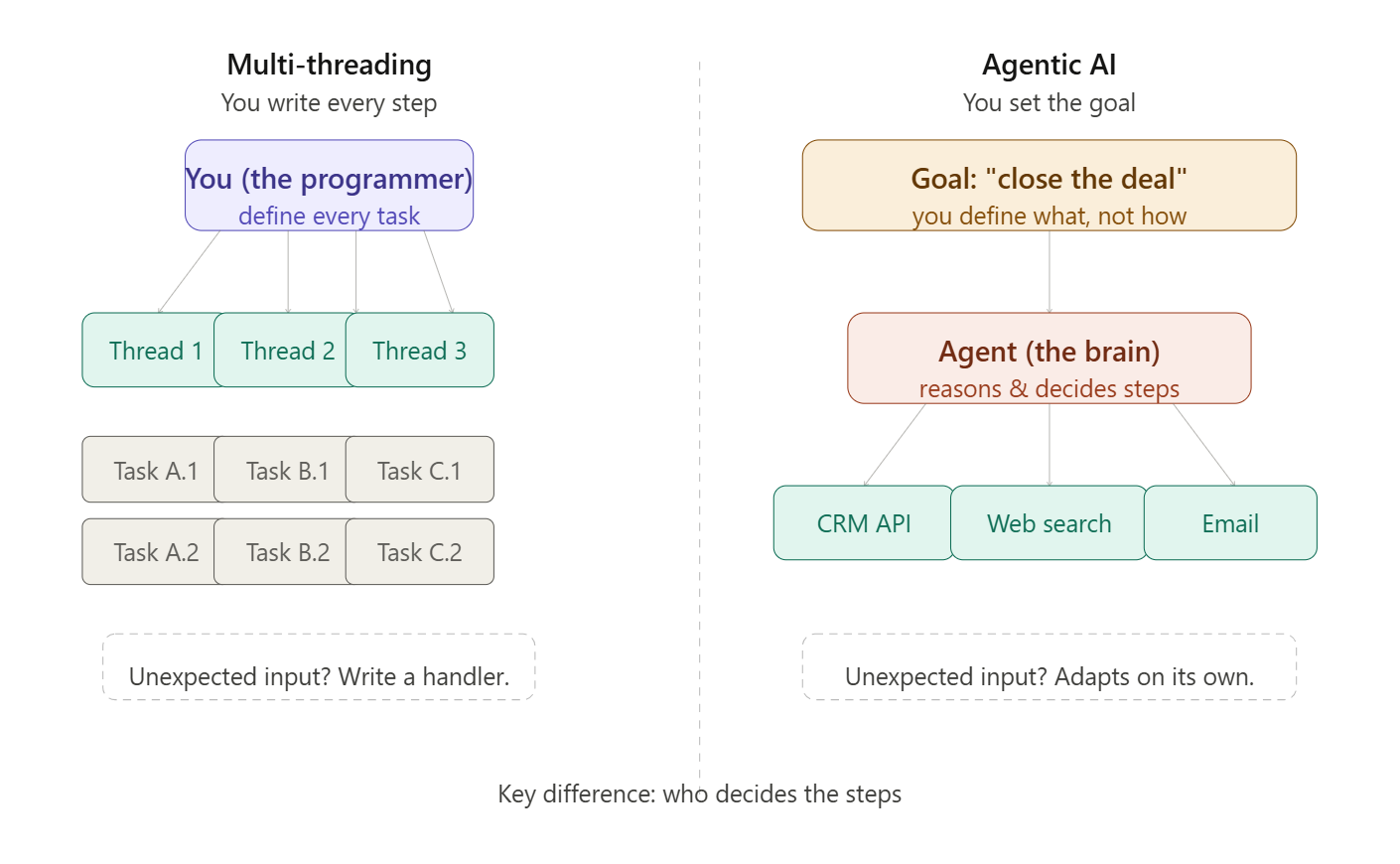
Here’s a concrete example. You tell an agent:
“Find all enterprise deals stuck in our CRM for more than 30 days, draft a follow-up email for each, and flag the ones where the last touchpoint was a competitor mention.”
The agent will: hit your CRM API, filter records, pull deal history, analyse notes, draft personalised emails, and return a prioritised list with drafts attached. You didn’t tell it how. You told it what, and it figured out the rest.
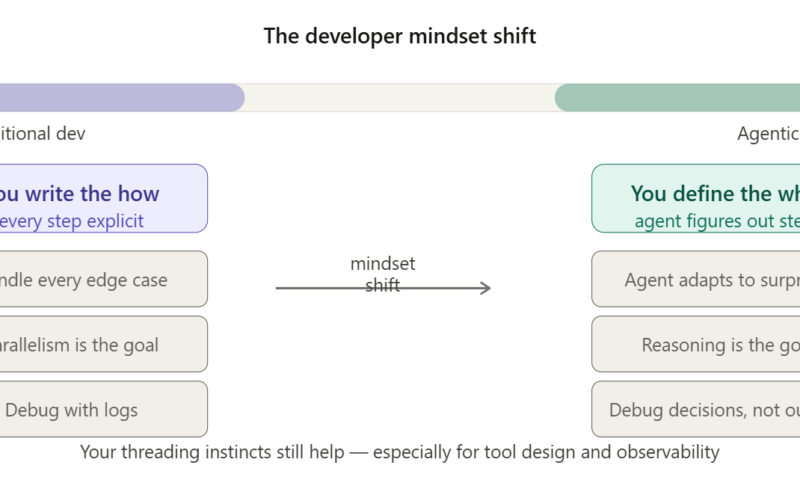
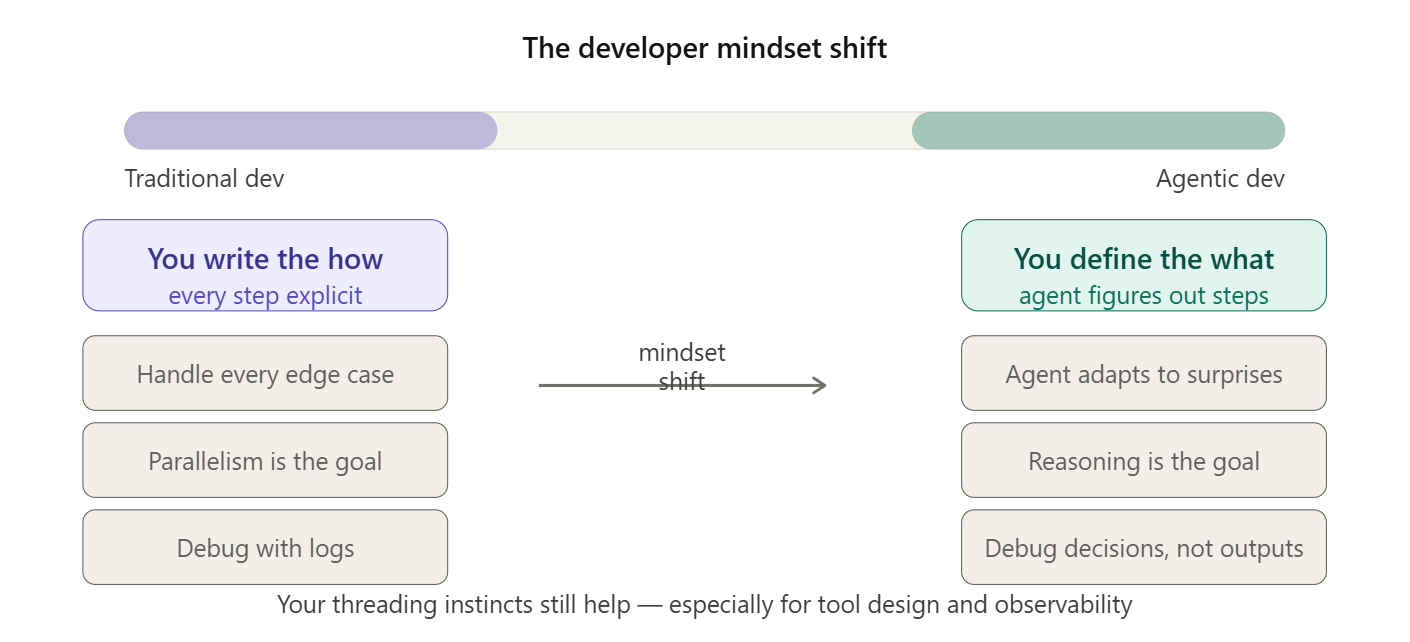
The Multi-Threading Trap
Here’s why the multi-threading analogy feels right at first: agentic systems do sometimes run things in parallel. Multiple agents can work simultaneously: one researching, one writing, one fact-checking. That part looks familiar.
But that’s where the similarity ends. Here’s the full picture:
| Multi-threading | Agentic AI | |
| Who decides the steps? | You (the programmer) | The agent itself |
| Does it run in parallel? | Yes, explicitly | Sometimes, not the point |
| Goal-driven? | No | Yes, core feature |
| Handles surprises? | No, needs coded logic | Yes, adapts dynamically |
| Uses external tools? | No | Yes, APIs, browsers, DBs |
| Can it reason? | No | Yes, that’s the whole game |
The killer difference? In multi-threading, you’re still the brain. You decide what each thread does. You write every decision point. If something unexpected happens, you have to handle it in code like a try/catch, a fallback, a retry loop. In agentic AI, the agent is the brain. It reads the situation, decides what to do next, and adapts when things go sideways without you writing that logic explicitly.
Real Enterprise Example:
A manufacturing company has an agent connected to SAP, email, and their supplier database. When inventory for a critical component drops below threshold, the agent doesn’t just notify someone, it checks current supplier pricing, compares lead times, drafts a purchase order, and routes it for human approval only if the amount exceeds a set limit.
Multi-threading version: A scheduled job polls inventory levels and triggers a notification. A human logs in, checks prices manually, creates the PO.
Agentic version: The agent handles the entire decision chain. You just approve.
“Okay, But What About Multi-Agent Systems?”
Now you’re asking the right question. When you have multiple agents working together, it does start looking more like multi-threading in structure, at least.
- Agent A pulls and cleans raw data from your data warehouse
- Agent B runs competitive analysis using web search
- Agent C synthesises both into an executive briefing
- All three run concurrently. Results merge at the end.
Sound familiar? It should. But here’s the key: each agent is still reasoning about its task, not just executing pre-written logic. If Agent B hits a paywalled article, it doesn’t crash – it finds an alternative source. If Agent C gets conflicting inputs, it flags the contradiction rather than blindly merging.
The parallelism is real. But the intelligence inside each “thread” is what makes it different.
TL;DR
Multi-threading: you write the what AND the how, then parallelise the execution.
Agentic AI: you write the what, the agent figures out the how, and adapts when reality doesn’t match the plan.