AI models are constantly surprising us – but how smart are they, really?
A recent infographic from Visual Capitalist ranks 24 leading AI systems by their performance on the Mensa Norway IQ test, revealing that even the best AI can outperform the average human.
AI Intelligence, by the Numbers
Visual Capitalist’s analysis shows AI models scoring across categories:
“Highly intelligent” class (>130 IQ)
“Genius” level (>140 IQ) with the top performers
Models below 100 IQ still fall in average or above-average ranges
For context, the average adult human IQ is 100, with scores between 90–110 considered the norm.
Humans vs. Machines: A Real-World Anecdote
Imagine interviewing your colleague, who once aced her undergrad finals with flying colors – she might score around 120 IQ. She’s smart, quick-thinking, adaptable.
Now plug her into a Mensa Norway-style test. She does well but places below the top AI models.
That’s where the surprise comes in: these AI models answer complex reasoning puzzles in seconds, with more consistency than even the smartest human brains. They’re in that “genius” club – but wholly lacking human intuition, creativity, or emotion.
What This IQ Comparison Really Shows
Insight
Why It Matters
AI excels at structured reasoning tests
But real-world intelligence requires more: creativity, ethics, emotional understanding.
AI IQ is a performance metric – not character
Models are powerful tools, not sentient beings.
Human + AI = unbeatable combo
Merging machine rigor with human intuition unlocks the best outcomes.
Caveats: Why IQ Isn’t Everything
These AI models are trained on test formats – they’re not “thinking” or “understanding” in a human sense.
IQ tests don’t measure emotional intelligence, empathy, or domain-specific creativity.
A “genius-level” AI might ace logic puzzles, but still struggle with open-ended tasks or novel situations.
Key Takeaway
AI models are achieving IQ scores that place them alongside the brightest humans – surpassing 140 on standardized Mensa-style tests . But while they shine at structured reasoning, they remain tools, not people.
The real power lies in partnering with them – combining human creativity, ethics, and context with machine precision. That’s where true innovation happens.
In the rapidly evolving field of artificial intelligence (AI), Large Language Models (LLMs) have steadily become the cornerstone of numerous advancements. From chatbots to complex analytics, LLMs are redefining how we interact with technology. One of the most noteworthy recent developments is the release of Llama 3 405B, which aims to bridge the gap between closed-source and open-weight models in the LLM category.
Image credit: Maxime Labonne (https://www.linkedin.com/in/maxime-labonne/)
This blog aims to explore the current landscape of LLMs, comparing closed-source and open-weight models, and delve into the unique roles played by small language models. Additionally, we’ll touch on the varied use-cases and applications of these models, culminating in a reasoned conclusion about the merits and drawbacks of closed vs. open-weight models.
Recent Developments in LLMs
Llama 3 405B stands out as a significant breakthrough in the LLM space, especially in the context of open-weight models. With 405 billion parameters, Llama 3 delivers robust performance that rivals, and in some cases surpasses, leading closed-source models. The shift towards adequately open models like Llama 3 highlights a broader trend in AI towards transparency, collaboration, and reproducibility.
Major players that offer continuous evolution of LLMs are:
GPT-4 from OpenAI remains a leading closed-source model offering general-purpose applications with multi-modal capabilities
Llama 3 405B developed by Meta AI, reportedly matches or exceeds the performance of some closed-source models.
Similarly, we have Google PaLM 2 and Anthropic Claude 2, 3.5 models show strong performance in various tasks.
Closed-Source vs. Open-Weight Models
Closed-Source Models
Definition: Closed-source models are proprietary and usually not accessible for public scrutiny or modification. The company or organization behind the model keeps the underlying code and often the training data private.
Examples:
GPT-4 (OpenAI)
Claude3.5 (Anthropic AI)
Pros:
Performance: Often optimized to achieve peak performance through extensive resources and dedicated teams.
Security: Better control over the model can yield heightened security and compliance with regulations.
Support and Integration: Generally come with robust support options and seamless integration capabilities.
Cons:
Cost: Typically expensive to use, often based on a subscription or pay-per-use model.
Lack of Transparency: Limited insight into the model’s workings, which can be a barrier to trustworthiness.
Dependency: Users become reliant on the provider for updates, fixes, and enhancements.
Open-Weight Models
Definition: Open-weight models, often referred to as open-source models, have their weights accessible to the public. This openness allows researchers and developers to understand, modify, and optimize the models as needed.
Examples:
Llama 3 405B
BERT
GPT-Neo and GPT-J (EleutherAI)
Pros:
Transparency: Enhanced understanding and ability to audit the model.
Cost Efficiency: Often free to use or available at a lower cost.
Innovation: Community-driven improvements and customizations are common.
Cons:
Resource Intensive: May require significant resources to implement and optimize effectively.
Security Risks: More exposure to potential vulnerabilities.
Lack of Support: May lack the direct support and resources of commercial models.
Small Language Models
While much attention is given to LLMs, small language models still play a crucial role, particularly when resources are constrained or specific, narrowly defined tasks are in focus.
Key Characteristics of Small Language Models:
Limited Parameters: Typically fewer parameters, making them lighter and faster.
Targeted Applications: Effective for specific use cases like dialogue systems, sentiment analysis, or keyword extraction.
Popular Small Language Models:
DistilBERT: A distilled version of BERT that is smaller and faster while retaining much of its performance
TinyBERT: Another compressed version of BERT, designed for edge devices
GPT-Neo: A family of open-source models of various sizes, offering a range of performance-efficiency trade-offs
Advantages of Small Language Models:
Reduced computational requirements
Faster inference times
Easier deployment on edge devices or resource-constrained environments
Lower carbon footprint
Conclusion: Closed vs. Open Source
The choice between closed-source and open-source LLMs depends on various factors, including the specific use case, available resources, and organizational priorities. Closed-source models often offer superior performance and ease of use, while open-source models provide greater flexibility, customization, and cost-efficiency.
As the LLM landscape continues to evolve, we can expect to see further convergence between closed-source and open-source models, as well as the emergence of specialized models for specific tasks.
Meta, the parent company of Facebook, unveiled the latest version of LLaMa 2 for research and commercial purposes. It’s released as open-source unlike OpenAI GPT / Google Bard which is proprietary.
What is LLaMa?
LLaMa (Large Language Model Meta AI) is an open-source language model built by Meta’s GenAI team for research. LLaMa 2 which is newly released for research and commercial uses.
Difference between LLaMa and LLaMa 2
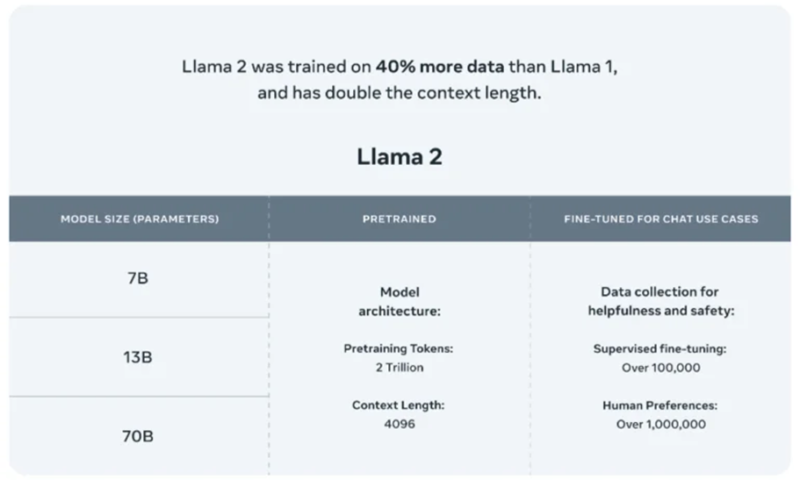
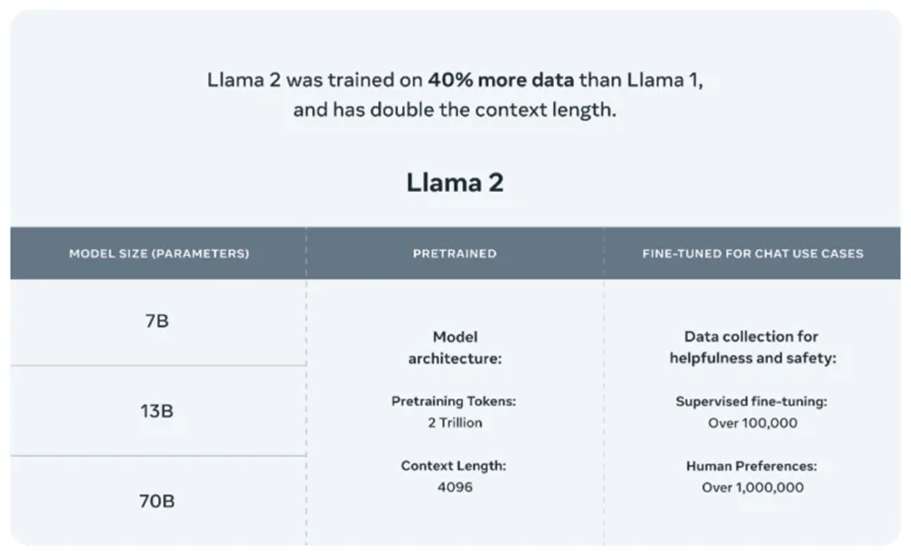
LLaMa 2 model was trained on 40% more data than its predecessor. Al-Dahle (vice president at Meta who is leading the company’s generative AI work) says there were two sources of training data: data that was scraped online, and a data set fine-tuned and tweaked according to feedback from human annotators to behave in a more desirable way. The company says it did not use Meta user data in LLaMA 2, and excluded data from sites it knew had lots of personal information.
Newly released LLaMa 2 models will not only further accelerate the LLM research work but also enable enterprises to build their own generative AI applications. LLaMa 2 includes 7B, 13B and 70B models, trained on more tokens than LLaMA, as well as the fine-tuned variants for instruction-following and chat.
According to Meta, its LLaMa 2 “pretrained” models are trained on 2 trillion tokens and have a context window of 4,096 tokens (fragments of words). The context window determines the length of the content the model can process at once. Meta also says that the LLaMa 2 fine-tuned models, developed for chat applications similar to ChatGPT, have been trained on “over 1 million human annotations.”
Databricks highlights the salient features of such open-source LLMs:
No vendor lock-in or forced deprecation schedule
Ability to fine-tune with enterprise data, while retaining full access to the trained model
Model behavior does not change over time
Ability to serve a private model instance inside of trusted infrastructure
Tight control over correctness, bias, and performance of generative AI applications
Microsoft says that LLaMa 2 is the latest addition to their growing Azure AI model catalog. The model catalog, currently in public preview, serves as a hub of foundation models and empowers developers and machine learning (ML) professionals to easily discover, evaluate, customize and deploy pre-built large AI models at scale.
OpenAI GPT vs LLaMa
A powerful open-source model like LLaMA 2 poses a considerable threat to OpenAI, says Percy Liang, director of Stanford’s Center for Research on Foundation Models. Liang was part of the team of researchers who developed Alpaca, an open-source competitor to GPT-3, an earlier version of OpenAI’s language model.
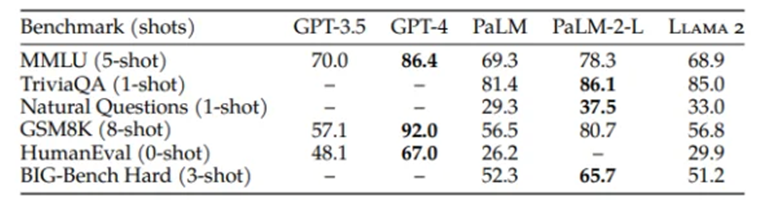
“LLaMA 2 isn’t GPT-4,” says Liang. Compared to closed-source models such as GPT-4 and PaLM-2, Meta itself speaks of “a large gap in performance”. However, ChatGPT’s GPT-3.5 level should be reached by Llama-2 in most cases. And, Liang says, for many use cases, you don’t need GPT-4.
A more customizable and transparent model, such as LLaMA 2, mighthelp companies create products and services faster than a big, sophisticated proprietary model, he says.
“To have LLaMA 2 become the leading open-source alternative to OpenAI would be a huge win for Meta,” says Steve Weber, a professor at the University of California, Berkeley.
LLaMA 2 also has the same problems that plague all large language models: a propensity to produce falsehoods and offensive language. The fact that LLaMA 2 is an open-source model will also allow external researchers and developers to probe it for security flaws, which will make it safer than proprietary models, Al-Dahle says.
With that said, Meta has set to make its presence felt in the open-source AI space as it has announced the release of the commercial version of its AI model LLaMa. The model will be available for fine-tuning on AWS, Azure and Hugging Face’s AI model hosting platform in pretrained form. And it’ll be easier to run, Meta says — optimized for Windows thanks to an expanded partnership with Microsoft as well as smartphones and PCs packing Qualcomm’s Snapdragon system-on-chip. The key advantage of on-device AI is cost reduction (cloud per-query costs) and data security (as data solely remain on-device)
LLaMa can turn out to be a great alternative for pricy proprietary models sold by OpenAI like ChatGPT and Google Bard.