Meta’s Large Language Model – LLaMa 2 released for enterprises
Meta, the parent company of Facebook, unveiled the latest version of LLaMa 2 for research and commercial purposes. It’s released as open-source unlike OpenAI GPT / Google Bard which is proprietary.
What is LLaMa?
LLaMa (Large Language Model Meta AI) is an open-source language model built by Meta’s GenAI team for research. LLaMa 2 which is newly released for research and commercial uses.
Difference between LLaMa and LLaMa 2
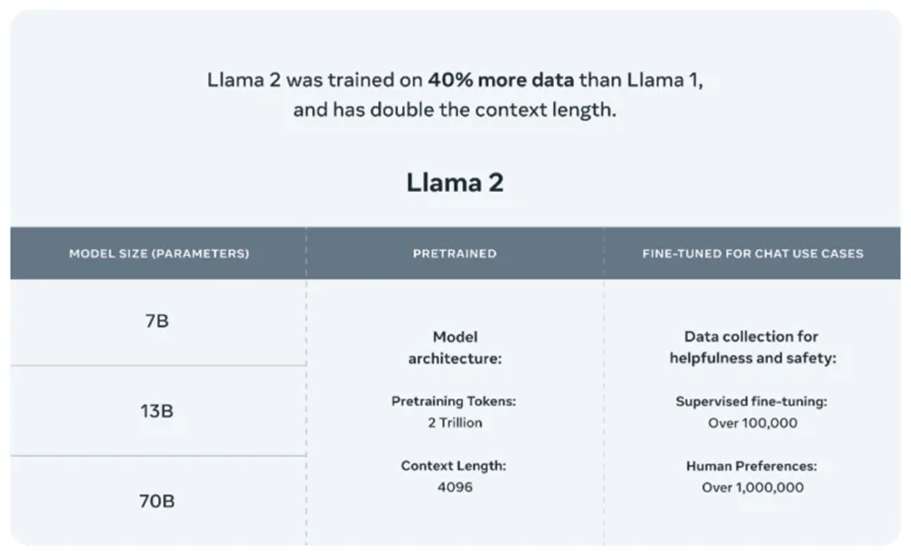
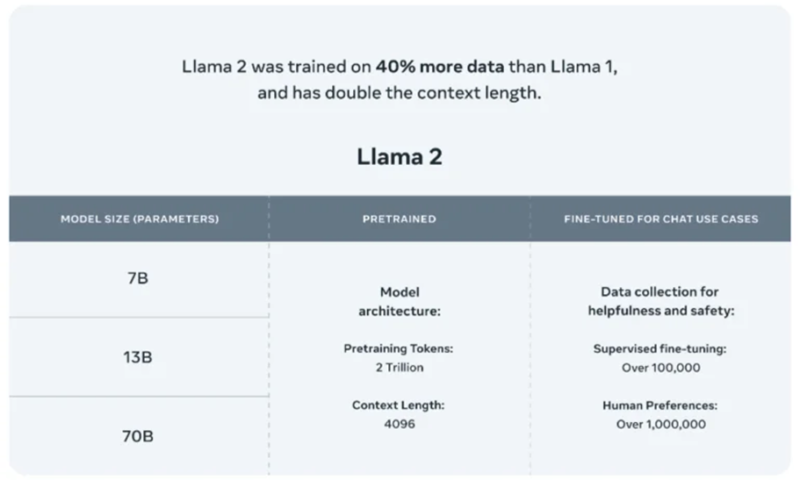
LLaMa 2 model was trained on 40% more data than its predecessor. Al-Dahle (vice president at Meta who is leading the company’s generative AI work) says there were two sources of training data: data that was scraped online, and a data set fine-tuned and tweaked according to feedback from human annotators to behave in a more desirable way. The company says it did not use Meta user data in LLaMA 2, and excluded data from sites it knew had lots of personal information.
Newly released LLaMa 2 models will not only further accelerate the LLM research work but also enable enterprises to build their own generative AI applications. LLaMa 2 includes 7B, 13B and 70B models, trained on more tokens than LLaMA, as well as the fine-tuned variants for instruction-following and chat.
According to Meta, its LLaMa 2 “pretrained” models are trained on 2 trillion tokens and have a context window of 4,096 tokens (fragments of words). The context window determines the length of the content the model can process at once. Meta also says that the LLaMa 2 fine-tuned models, developed for chat applications similar to ChatGPT, have been trained on “over 1 million human annotations.”
Databricks highlights the salient features of such open-source LLMs:
- No vendor lock-in or forced deprecation schedule
- Ability to fine-tune with enterprise data, while retaining full access to the trained model
- Model behavior does not change over time
- Ability to serve a private model instance inside of trusted infrastructure
- Tight control over correctness, bias, and performance of generative AI applications
Microsoft says that LLaMa 2 is the latest addition to their growing Azure AI model catalog. The model catalog, currently in public preview, serves as a hub of foundation models and empowers developers and machine learning (ML) professionals to easily discover, evaluate, customize and deploy pre-built large AI models at scale.
OpenAI GPT vs LLaMa
A powerful open-source model like LLaMA 2 poses a considerable threat to OpenAI, says Percy Liang, director of Stanford’s Center for Research on Foundation Models. Liang was part of the team of researchers who developed Alpaca, an open-source competitor to GPT-3, an earlier version of OpenAI’s language model.
“LLaMA 2 isn’t GPT-4,” says Liang. Compared to closed-source models such as GPT-4 and PaLM-2, Meta itself speaks of “a large gap in performance”. However, ChatGPT’s GPT-3.5 level should be reached by Llama-2 in most cases. And, Liang says, for many use cases, you don’t need GPT-4.
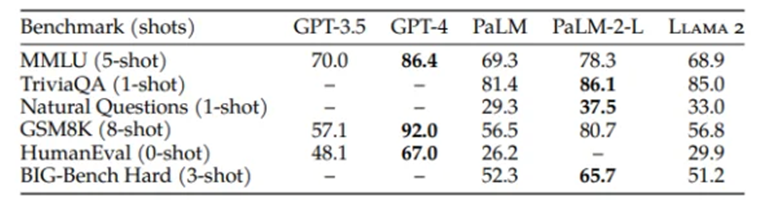
A more customizable and transparent model, such as LLaMA 2, might help companies create products and services faster than a big, sophisticated proprietary model, he says.
“To have LLaMA 2 become the leading open-source alternative to OpenAI would be a huge win for Meta,” says Steve Weber, a professor at the University of California, Berkeley.
LLaMA 2 also has the same problems that plague all large language models: a propensity to produce falsehoods and offensive language. The fact that LLaMA 2 is an open-source model will also allow external researchers and developers to probe it for security flaws, which will make it safer than proprietary models, Al-Dahle says.
With that said, Meta has set to make its presence felt in the open-source AI space as it has announced the release of the commercial version of its AI model LLaMa. The model will be available for fine-tuning on AWS, Azure and Hugging Face’s AI model hosting platform in pretrained form. And it’ll be easier to run, Meta says — optimized for Windows thanks to an expanded partnership with Microsoft as well as smartphones and PCs packing Qualcomm’s Snapdragon system-on-chip. The key advantage of on-device AI is cost reduction (cloud per-query costs) and data security (as data solely remain on-device)
LLaMa can turn out to be a great alternative for pricy proprietary models sold by OpenAI like ChatGPT and Google Bard.
References:
https://ai.meta.com/llama/?utm_pageloadtype=inline_link
https://www.technologyreview.com/2023/07/18/1076479/metas-latest-ai-model-is-free-for-all/
https://www.databricks.com/blog/building-your-generative-ai-apps-metas-llama-2-and-databricks