Introduction to Sentiment Analysis using Stanford NLP
Nowadays consumer forums, surveys, social media are generating huge text content like never before compared to the last decade.
Interesting use-cases can be brand monitoring using social media data, voice of customer analysis etc.
Thanks to research in Natural Language Processing (NLP), many algorithms, libraries have been written in programming languages such as Python for companies to discover new insights about their products and services.
Popular NLP Libraries in Python
NLTK (Natural Language Toolkit) is a huge corpus of human language data built as open-source package for Python language. It performs tasks such as tokenization, parsing, classification, tagging, semantic reasoning.
There are other prominent libraries in place. For instance, Textblob is built on top of NLTK package. And, there are other libraries such as Spacy, Gensim, Stanford Core NLP.
Common NLP Tasks
In a nutshell, there are many text related tasks we can think of such as tokenization, parts of speech (pos) tagger, named entity recognition, coreference resolution, sentiment analysis, stemming, lemmatization, stopwords removal, singularize/pluralize, ngram, spellcheck, summarizing text, topic modeling and the kind of linguistic languages we’re dealing with.
In this article, I’d like to share a simple, quick way to perform sentiment analysis using Stanford NLP.
The outcome of a sentence can be positive, negative and neutral. In general sense, this is derived based on two measures: a) Polarity and b) Subjectivity.
Polarity score ranges between -1 and 1, indicating sentiment as negative to neutral to positive whereas Subjectivity ranges between 0 and 1 indicating objective when it is closer to 0 – factual information and subjective when closer to 1.
Stanford NLP is built on Java but have Python wrappers and is a collection of pre-trained models. Let’s dive into few instructions…
- As a pre-requisite, download and install Java to run the Stanford CoreNLP Server.
- Download Stanford CoreNLP English module at https://stanfordnlp.github.io/CoreNLP/download.html#getting-a-copy
- Navigate to its path in your downloaded folder. Unzip the files. Go to your command prompt and type the following command to run its server. Note: -mx4g option is to state 4 gigabytes memory to be used.
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 50000
Launch your Python Jupyter notebook or IDE (Ex: Spyder) and run down this code. Ensure you install StanfordCoreNLP package using PIP install command.
from pycorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP('http://localhost:9000')
text = "The intent behind the movie was great, but it could have been better"
results = nlp.annotate(text,properties={
'annotators':'sentiment, ner, pos',
'outputFormat': 'json',
'timeout': 50000,
})
for s in results["sentences"]:
print("{} : {}".format(" ".join(t["word"] for t in s["tokens"]),s["sentiment"]))
Annotate allows us to call specific NLP tasks such as Sentiment analysis. It returns output in JSON format.
Once you run the code, you can terminate the Java server by typing Ctrl + C and hitting enter in the command prompt.
Stanford NLP supports multiple languages other than English. You can follow the documentation provided at https://stanfordnlp.github.io/CoreNLP/
For a sample quick analysis, try this link which connects you to Stanford NLP http://corenlp.run/ instance. Type a sentence and explore the visual representation of some of the analysis.
You can refer the same sample code on my GitHub: https://github.com/coffeewithshiva/Sentiment_Analysis_Stanford_NLP
On Textblob, I came across the below GitHub which might be extensively useful: https://github.com/shubhamjn1/TextBlob/blob/master/Textblob.ipynb
Happy NLP!
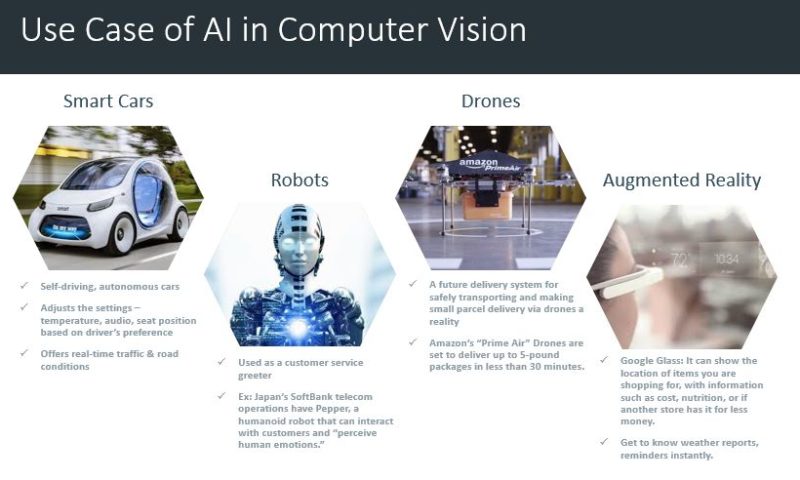
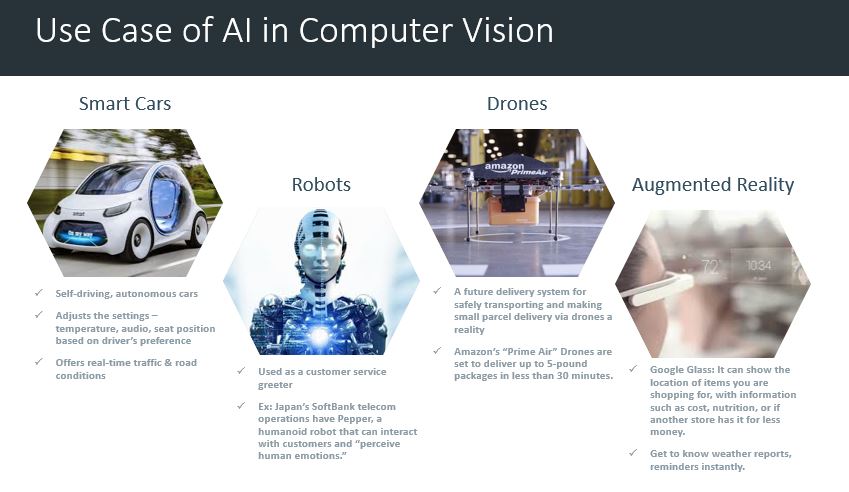 1. Computer Vision – Smart Cars (Autonomous Cars): IBM survey results say 74% expected that we would see smart cars on the road by 2025. It might adjust the internal settings — temperature, audio, seat position, etc. — automatically based on the driver, report and even fix problems itself, drive itself, and offer real time advice about traffic and road conditions.
1. Computer Vision – Smart Cars (Autonomous Cars): IBM survey results say 74% expected that we would see smart cars on the road by 2025. It might adjust the internal settings — temperature, audio, seat position, etc. — automatically based on the driver, report and even fix problems itself, drive itself, and offer real time advice about traffic and road conditions.